

Problem:
- Over 8 tag sitemaps listed in sitemap_index.xml
- Hundreds of /tag/ URLs indexed by Google.
- Hundreds of /tag/ URLs indexed by Google (e.g., /tag/mstr/, /tag/austria/, /tag/immutable/)
- Low SEO value tag pages: thin content, no backlinks, no unique metadata
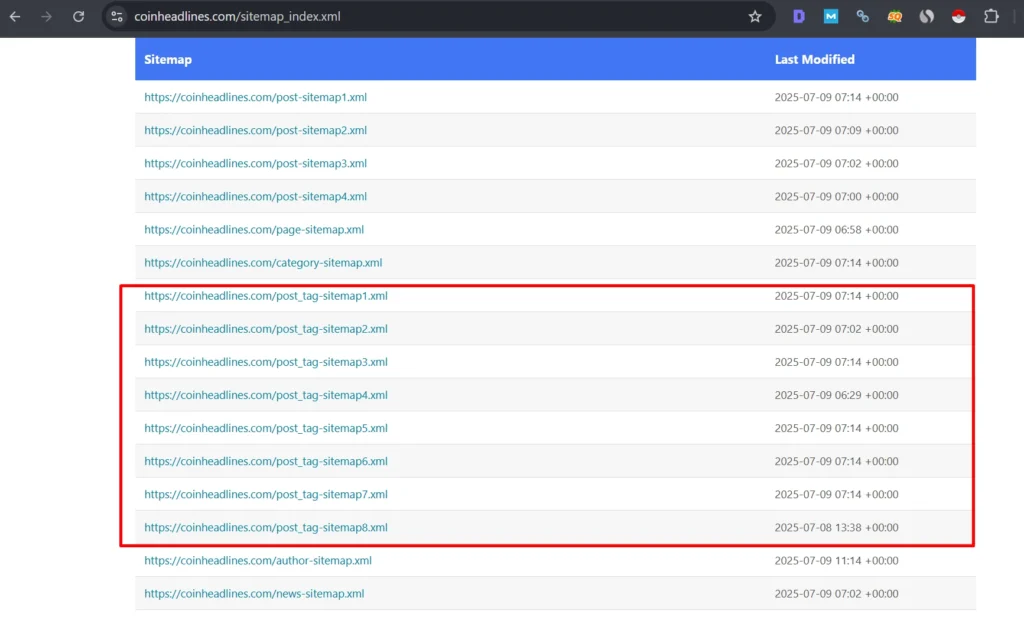
These pages were:
- Consuming crawl budget
- Risking duplicate/thin content penalties
- Potentially competing with actual articles and category pages
Potential SEO Concerns:
While it’s good that Google is indexing your content, tag archives can cause SEO issues if not handled properly, such as:
- Thin Content/Duplicate Content Risk
Tag pages often show post excerpts or listings only, which can appear low-value or duplicate compared to category or actual post pages. - Wasted Crawl Budget
Googlebot might spend time crawling dozens or hundreds of tag pages that don’t add unique value. - Keyword Cannibalization
If multiple tag pages compete with category or post pages for the same keywords, it may dilute your rankings.
Solution (Using Rank Math)
I implemented a clean and SEO-compliant fix using Rank Math settings in WordPress:
✅ Step 1: Applied noindex, follow to Tag Archives
- Set tag pages to noindex under:
Rank Math → Titles & Meta → Tags
✅ Step 2: Removed Tag Sitemaps from Search Engines
- Disabled tag sitemap generation under:
Rank Math → Sitemap Settings → Tags → Disable
✅ Step 3: Kept Robots.txt Clean
Avoided using Disallow: /tag/ to ensure Google can still crawl and see the noindex directive.
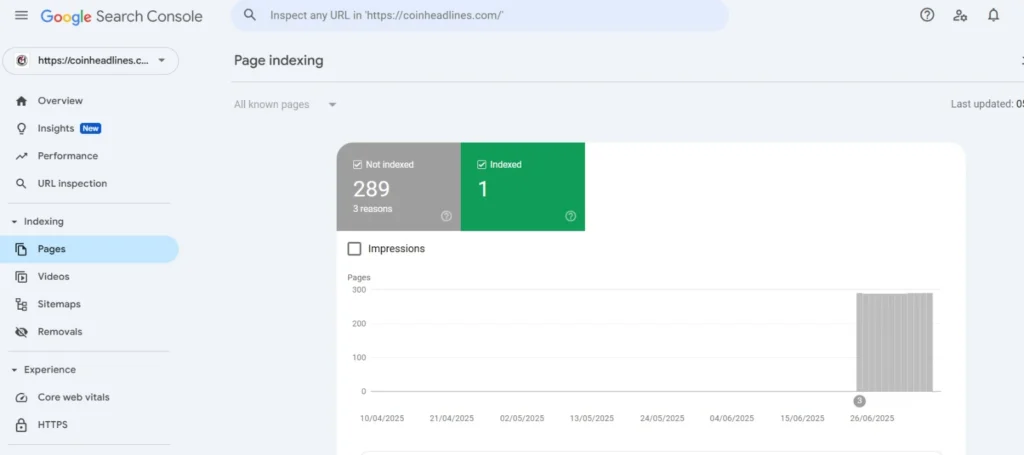
Before:
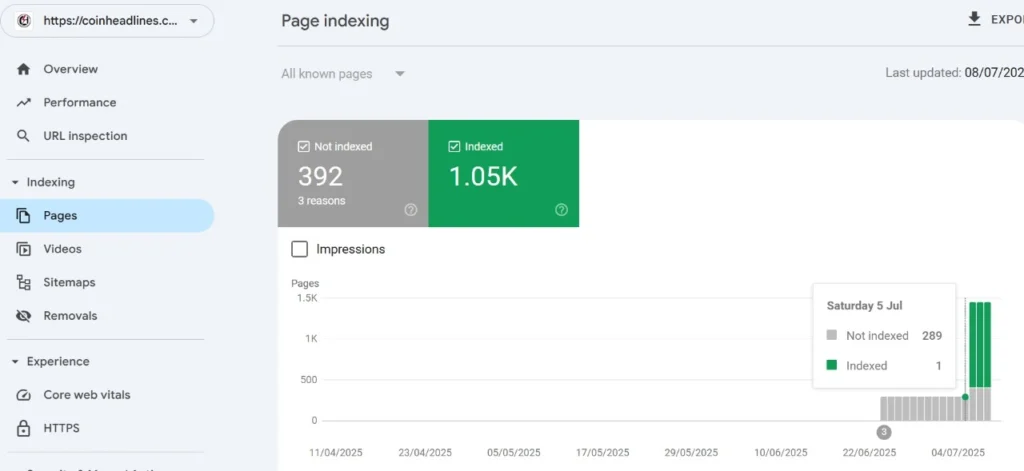
After:
Results (Within 10–15 Days)
- Over 90% of tag pages dropped from Google’s index (confirmed via Search Console)
- No loss in organic traffic or keyword rankings
- Improved crawl frequency for high-value articles and categories
- Leaner, more focused XML sitemap index
Key Takeaway
Proper use of “noindex, follow” with sitemap management is far more effective than blindly blocking URLs via robots.txt.
Rank Math made it efficient, safe, and SEO-friendly.
{kind=link}